El estudio que más me ha marcado este año es On the Biology of a Large Language Model (marzo de 2025) de Anthropic. En él, los investigadores presentan un método para observar el “pensamiento interno” de los modelos. Sus hallazgos han transformado mi manera de diseñar prompts para herramientas de programación como Claude Code. He aprendido que, para determinar el siguiente “token”, los LLM procesan múltiples soluciones en paralelo y las agregan en el resultado final, algo muy diferente a cómo pensamos nosotros.
Resumen de «Sobre La Biología de los LLM»
El desafío es que las neuronas de Claude 3.5 Haiku, el modelo estudiado en esta investigación, son polisemánticas: una sola neurona puede representar varios conceptos a la vez. Para solucionarlo, crearon un “modelo de reemplazo” que utiliza características (features) más interpretables.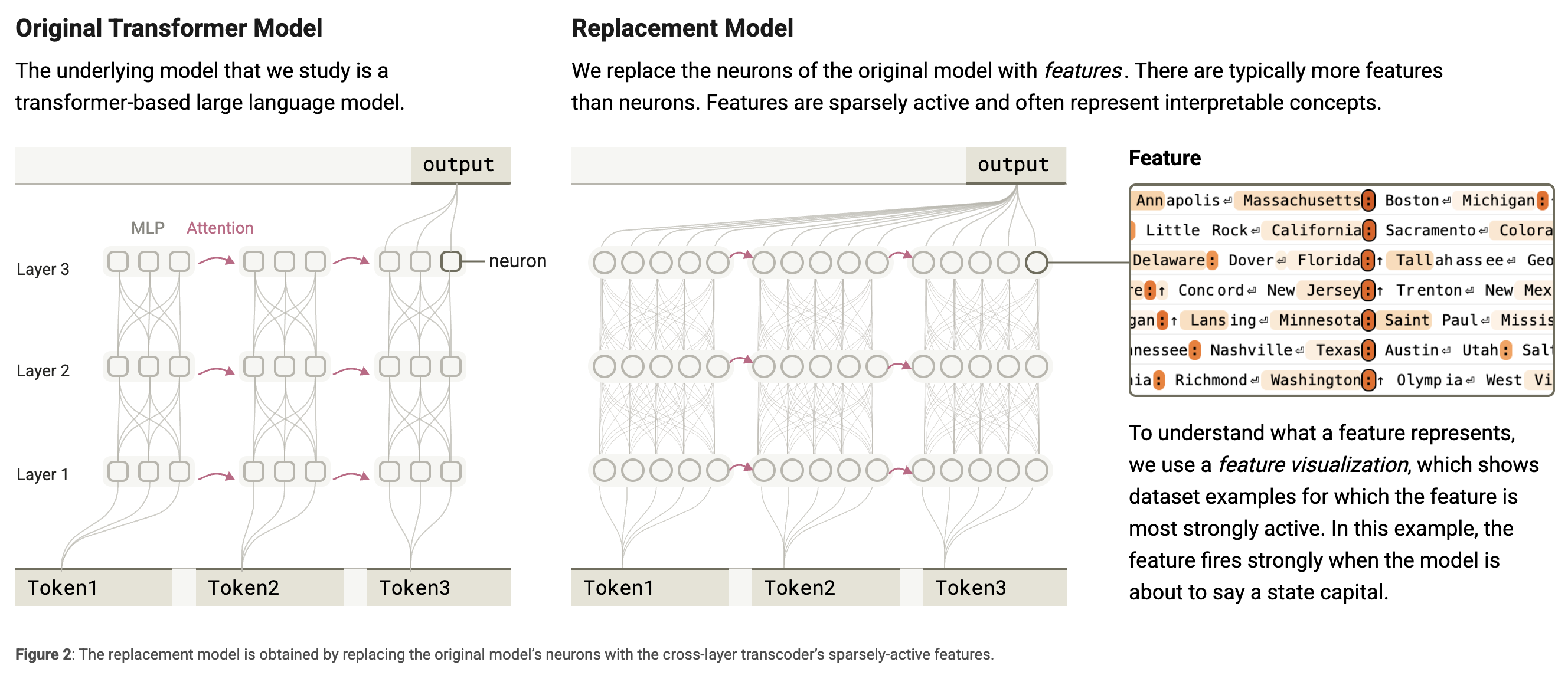
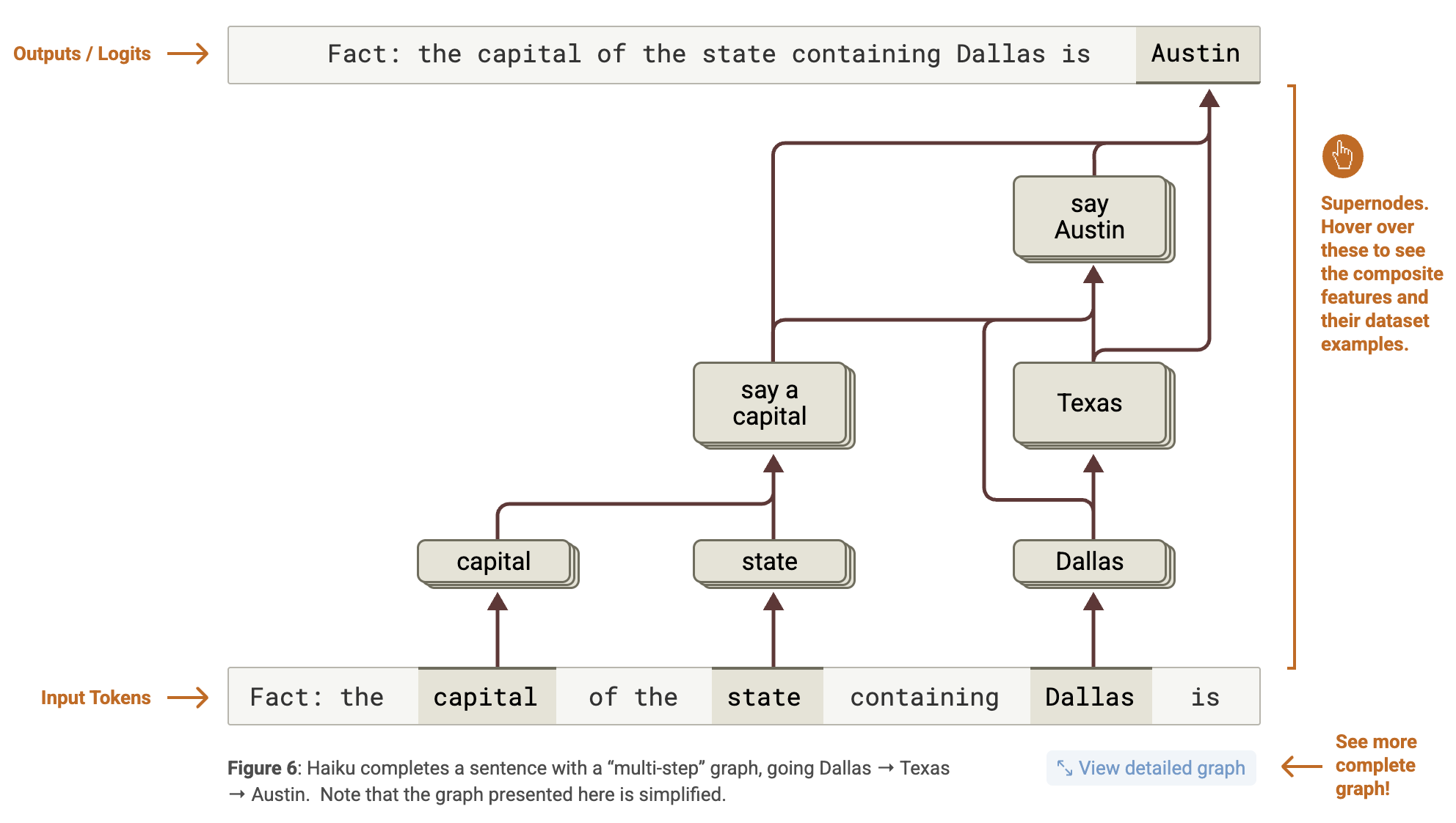
- Paso 1: En paralelo, identifica que Dallas está en Texas y activa el concepto de “decir una capital”.
- Paso 2: Combina ambos para llegar a “Austin”.
¿Cómo suma un LLM dos números?
El caso de la suma es, en mi opinión, el más interesante.
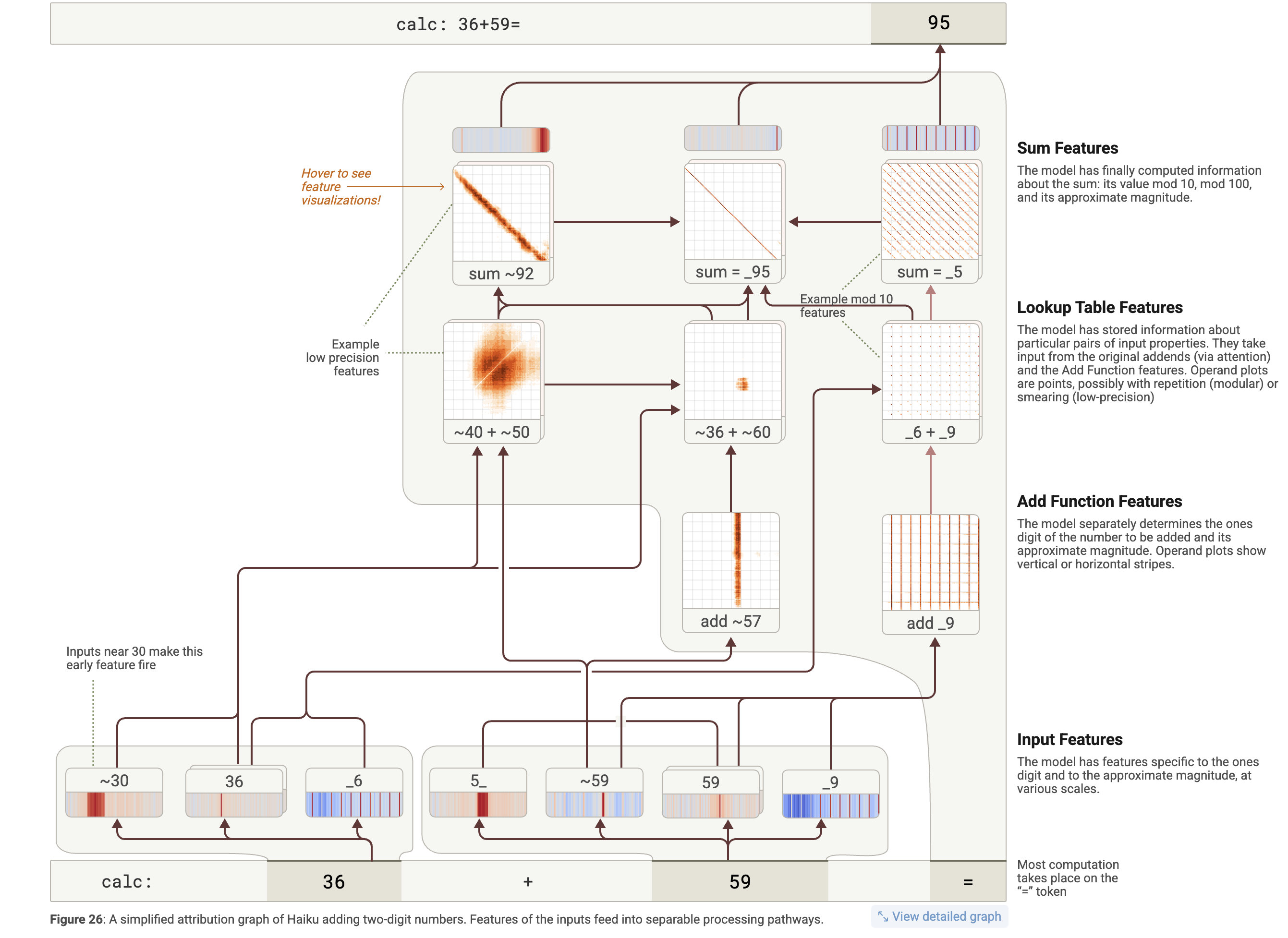
36 + 59 = ___
Mientras que los humanos usamos un algoritmo secuencial (sumar unidades y
“llevarse una” a las decenas), el LLM divide el problema en vías paralelas.
- Vía de las unidades: Características de “tabla de búsqueda” detectan que un número termina en 6 y el otro en 9, por lo que el resultado debe terminar en 5.
- Vía de aproximación (1): Algunas características detectan que 36 es “cerca de 40” y 59 es “cerca de 50”, sugiriendo que el resultado ronda el 90.
- Vía de aproximación (2): Otras características detectan que el problema es como ~36 + ~60, sugiriendo que el resultado debe rondar el 96.
=.
Cómo aplico yo el estudio a la programación
Esta sección contiene mi especulación a partir del estudio. On the Biology of
a Large Language
Model
se enfoca en el MLP, no en la atención.
Before coding, understand the context and commit to a BOLD aesthetic direction:
(Antes de programar, entiende el contexto y comprométete con una dirección estética ATREVIDA.)
Interpret creatively and make unexpected choices that feel genuinely designed for the context. No design should be the same.
(Interpreta con creatividad y haz decisiones inesperadas que se sientan auténticamente diseñadas para el contexto. Ningún diseño debe ser igual.)
Consejos prácticos
- Cuidado con la auto-explicación: Si pides a un modelo que explique cómo resolvió algo, su respuesta puede ser una “simulación”. El estudio demostró que el modelo decía haber sumado paso a paso cuando, por dentro, usó aproximaciones paralelas.
- Contexto rico = Mejores vías: Cuanto más rico sea el contexto, más vías de conocimiento especializado activarás en el modelo.
- Aprovecha el razonamiento paralelo: Obtendrás mejores resultados si permites que el modelo proponga varias opciones o piense paso a paso (Chain of Thought) para alinear sus procesos internos con la salida final.